Data Quality Monitoring

Data Quality Monitoring is the process organisations use to keep a check on health of the data in their system, eliminates data downtime by applying best practices of DevOps Observability to data pipelines.
What is data observability?
Developer Operations (lovingly referred to as DevOps) teams have become an integral component of most engineering organizations. DevOps teams remove silos between software developers and IT, facilitating the seamless and reliable release of software to production.
As organizations grow and the underlying tech stacks powering them become more complicated (think: moving from a monolith to a microservice architecture), it’s important for DevOps teams to maintain a constant pulse on the health of their systems. Observability speaks to this need, and refers to the monitoring, tracking, and triaging of incidents to prevent downtime.
As data systems become increasingly complex and companies ingest more and more data, data teams also need a holistic, end-to-end way to monitor, alert for, root cause, and prevent “data downtime” (in other words, periods of time where data is missing, inaccurate, stale, or otherwise erroneous) from affecting downstream data consumers.
Data observability, an organization’s ability to fully understand the health of the data in their system, eliminates data downtime by applying best practices of DevOps Observability to data pipelines. Like its DevOps counterpart, data observability uses automated monitoring, alerting, and triaging to identify and evaluate data quality and discoverability issues, leading to healthier pipelines and more productive data teams.
What does data observability look like in practice?
Like application observability’s three pillars (metrics, traces, and logs), data observability can be measured across five key pillars of data health. The five pillars of data observability are: freshness, distribution, volume, schema, and lineage. Together, these components provide valuable insight into the quality and reliability of your data.

- Freshness: Freshness seeks to understand how up-to-date your data tables are, as well as the cadence at which your tables are updated. Freshness is particularly important when it comes to decision-making; after all, stale data is basically synonymous with wasted time and money.
- Distribution: Distribution, in other words, a function of your data’s possible values, tells you if your data is within an accepted range. Data distribution gives you insight into whether or not your tables can be trusted based on what can be expected from your data.
- Volume: Volume refers to the completeness of your data tables and offers insights on the health of your data sources. If 200 million rows suddenly turns into 5 million, you should know.
- Schema: Changes in the organization of your data, in other words, schema, often indicates broken data. Monitoring who makes changes to these tables and when is foundational to understanding the health of your data ecosystem.
- Lineage: When data breaks, the first question is always “where?” Data lineage provides the answer by telling you which upstream sources and downstream ingestors were impacted, as well as which teams are generating the data and who is accessing it. Good lineage also collects information about the data (also referred to as metadata) that speaks to governance, business, and technical guidelines associated with specific data tables, serving as a single source of truth for all consumers.
Why do data teams need observability? Isn’t testing sufficient?
Data testing is the process of validating your assumptions about your data at different stages of the pipeline. Basic data testing methods include schema tests or custom data tests using fixed data, which can help ensure that ETLs run smoothly, confirm that your code is working correctly in a small set of well-known scenarios, and prevent regressions when code changes.
Data testing helps by conducting static tests for null values, uniqueness, referential integrity, and other common indicators of data problems. These tools allow you to set manual thresholds and encode your knowledge of basic assumptions about your data that should hold in every run of your pipelines.
But, much in the same way that unit tests alone are insufficient for software reliability, data testing by itself cannot prevent broken data pipelines. Relying on data testing to find issues in your data pipeline before you run analysis is equivalent to trusting unit and integration testing to identify buggy code before you deploy new software, but it’s insufficient in modern data environments. In the same way that you can’t have truly reliable software without application monitoring and observability across your entire codebase, you can’t achieve full data reliability without data monitoring and observability across your entire data infrastructure.
Rather than relying exclusively on testing, the best data teams are leveraging a dual approach, blending data testing with constant monitoring and observability across the entire pipeline. Here’s why modern data teams need both:
- Data changes, a lot. While testing can detect and prevent many issues, it is unlikely that a data engineer or analyst will be able to anticipate all eventualities during development, and even if she could, it would require an extraordinary amount of time and energy. In some ways, data is even harder to test than traditional software. The variability and sheer complexity of even a moderately sized dataset is huge. To make things more complicated, data also often comes from an “external” source that is bound to change without notice. Some data teams will struggle to even find a representative dataset that can be easily used for development and testing purposes given scale and compliance limitations. Observability fill these gaps by providing an additional layer of visibility into these inevitable — and potentially problematic — changes to your pipelines.
- End-to-end coverage is critical. For many data teams, creating a robust, high coverage test suite is extremely laborious and may not be possible or desirable in many instances — especially if several uncovered pipelines already exist. While data testing can work for smaller pipelines, it does not scale well across the modern data stack. Most modern data environments are incredibly complex, with data flowing from dozens of sources into a data warehouse or lake and then being propagated into BI/ML for end-user consumption or to other operational databases for serving. Along the way from source to consumption, data will go through a good number of transformations, sometimes into the hundreds. Data observability covers these “unknown unknowns”
- Data testing debt. While we all aspire to have great testing coverage in place, data teams will find that parts of their pipelines are not covered. For many data teams, no coverage will exist at all, as reliability often takes the backseat to speed in the early days of pipeline development. If key knowledge about existing pipelines lies with a few select (and often very early) members of your data team, retroactively addressing your testing debt will, at the very best, divert resources and energy that could have otherwise been spent on projects that move the needle for your team. At the very worst, fixing testing debt will be nearly impossible if many of those early members of your team are no longer with the company and documentation isn’t up to date. ML-based observability learns from past data and monitors new incoming data, teams are able to create visibility into existing pipelines with little to no investment and prior knowledge, as well as reduce the burden on data engineers and analysts to mitigate testing debt.
- Being the first to know about data quality issues in production.
- Fully understanding the impact of the issue.
- Fully understanding where the data broke.
- Taking action to fix the issue.
- Collecting learnings so over time you can prevent issues from occurring again, including information about key assets, data usage, accessibility, and reliability.
- It connects to your existing stack quickly and seamlessly and does not require modifying your pipelines, writing new code, or using a particular programming language. This allows quick time to value and maximum testing coverage without having to make substantial investments.
- It provides end-to-end coverage of your stack, from ingestion in the warehouse to ETL and the analytics layer. Data observability is only useful if it can monitor the health and reliability of data at each stage in the pipeline, as opposed to solely in the warehouse or BI layer. Strong data observability solutions will take this end-to-end approach.
- It monitors your data at-rest and does not require extracting the data from where it is currently stored. This allows the solution to be performant, scalable and cost-efficient. It also ensures that you meet the highest levels of security and compliance requirements.
- It requires minimal configuration and practically no threshold-setting. It uses ML models to automatically learn your environment and your data. It uses anomaly detection techniques to let you know when things break. It minimizes false positives by taking into account not just individual metrics, but a holistic view of your data and the potential impact from any particular issue. You do not need to spend resources configuring and maintaining noisy rules.
- It requires no prior mapping of what needs to be monitored and in what way. It helps you identify key resources, key dependencies, and key invariants through automatic, field-level lineage so that you get broad observability with little effort.
- It provides rich context that enables rapid triage and troubleshooting and effective communication with stakeholders impacted by data reliability issues. It doesn’t stop at “field X in table Y has values lower than Z today.”
- It prevents issues from happening in the first place by exposing rich information about data assets so that changes and modifications can be made responsibly and proactively through root cause and impact analysis.
- Understanding where in the pipeline data broke
- Identifying the root cause of a data incident, including buggy code, operational factors, and the data itself
- Answering questions from stakeholders around data health and quality:
- “What happened to this dashboard?”
- “Why didn’t my report update?”
- “Why do my calculations look funky?”
- “Which team updated this data set?”
- “Why did my pipeline break?”
- “Why is my data missing?!”
- Automatically mapping dependencies between upstream sources and the data warehouse / lake with downstream reports and dashboards, down to the field level
- Conducting impact analysis on data issues, i.e., understanding which reports or dashboards are connecting to an upstream data set and will be affected with pipelines break
- Giving a high-level overview of data reliability to key stakeholders to track operational analytics for your data environment
- Supplement testing by providing insurance for your data when unforeseen or silent incidents occur
What should you look for when selecting a data observability solution?
To facilitate quicker development of code and its underlying architecture, DevOps teams apply a feedback loop, called the DevOps lifecycle, that helps teams reliably deliver features aligned with business objectives at scale. Much in the same way that DevOps applies a continuous feedback loop to improving software, the Data Reliability lifecycle, an organization-wide approach to continuously and proactively improving data health, eliminates data downtime by applying best practices of DevOps to data pipelines.
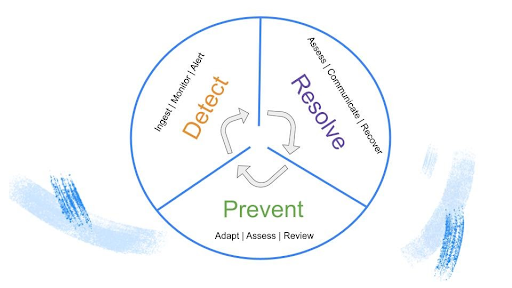
Data Observability addresses critical elements of the Data Reliability life cycle, including:
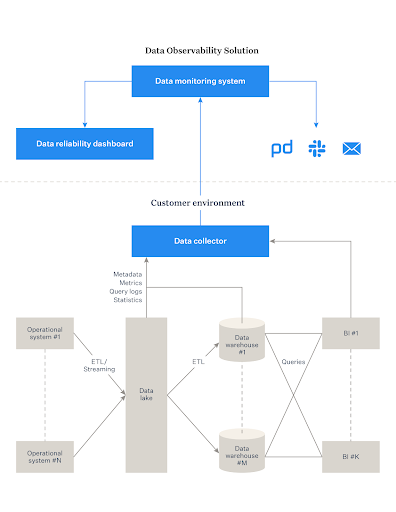
What are some common data observability use cases?
Much in the same way that the use cases for application performance monitoring tools like Datadog, New Relic, and AppDynamics span different functions, the ways in which data engineering, analytics, and analytics engineering teams leverage data observability vary depending on the needs of the business. At the end of the day, however, a data observability solution’s key functionality is to help data organizations deliver more trustworthy and reliable data.
Here are a few common use cases:

Molly Vorwerck
Head of Content
Monte Carlo


Featured Companies
Here are some amazing companies in the Data Quality Monitoring.
Automated real-time data validation and data quality monitoring for mo ...
Great Expectations helps data teams eliminate pipeline debt, through d ...